{kind=link}

In Data Structures and Algorithms we have studied several data structures like arrays, linked lists, queues, graphs and now we are covering advanced data structure that is B-Tree Data Structure. B-Tree is a self-balancing tree which is used to store and manage large datasets.
In this blog we will be covering introduction to B-Tree, properties of B-Tree, time and space complexity of B-Tree data structure, its operations and the implementation of it in C and C++.
What is B-Tree Data Structure?
A B-Tree data structure is a self-balancing search tree in which each node can contain more than one key and can have more than two children. It generalizes the concept of a binary search tree by allowing a node to store multiple keys and multiple child pointers.
B-Trees are optimized for systems that read and write large blocks of data. They are particularly well-suited for databases and file systems where minimizing disk I/O is crucial.
Example :
Imagine a library where books are organized on shelves by genre, with a limit on how many books each shelf can hold. If a shelf gets too full, it splits, and the middle book moves up to a higher shelf (parent node). The parent shelves guide you to the correct section of the library which is making it easy to find books. Just like in a B-Tree all the shelves stay organized and the structure remains balanced. This allows you to quickly search add, or remove books without going through the entire library.

Properties of B-Tree
Let the order of the B-tree be m. The order defines the maximum number of children a node can have.
Here are the essential properties:
- Every node can contain at most m-1 keys and m children.
- All leaves appear on the same level.
- All internal nodes (except root) have at least m/2 children.
- The root must have at least 2 children if it is not a leaf.
- Keys within a node are sorted in increasing order.
- Child pointers divide the keys into ranges (like a generalization of binary search).
Need of a B-Tree
Why not just use a Binary Search Tree?
Its general but still an interesting question to cover why actually B-Tree is required.
- BSTs become unbalanced with skewed data.
- Height of BST can grow, increasing access time to O(n).
- Disk access is expensive, and B-Trees reduce the height of the tree and hence the number of disk reads.
- B-Trees allow efficient range queries, making them suitable for database indexing.
Time and Space Complexity of B-Tree
Time and Space Complexity both are very important factors to analyze the efficiency of a B-Tree Data Structure
| Operation | Time Complexity | Explanation |
|---|---|---|
| Search | O(log n) | Balanced nature ensures logarithmic height. |
| Insert | O(log n) | May cause splitting, but still logarithmic. |
| Delete | O(log n) | May involve merging or redistribution. |
| Space | O(n) | Linear in number of keys stored. |

Operations on a B-Tree
In the given respective table for a B-tree data structure we are having all the basic operations which are required to manage the information.
| Operation | What it Does |
|---|---|
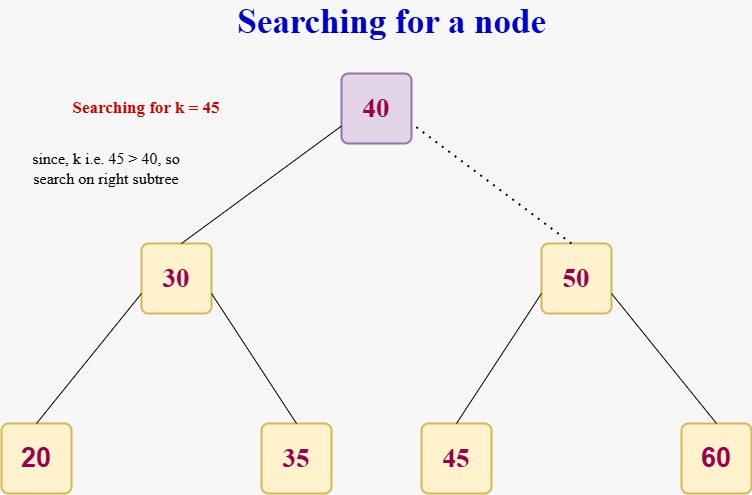
| Search | Looks for a key in the tree step by step from top to bottom |
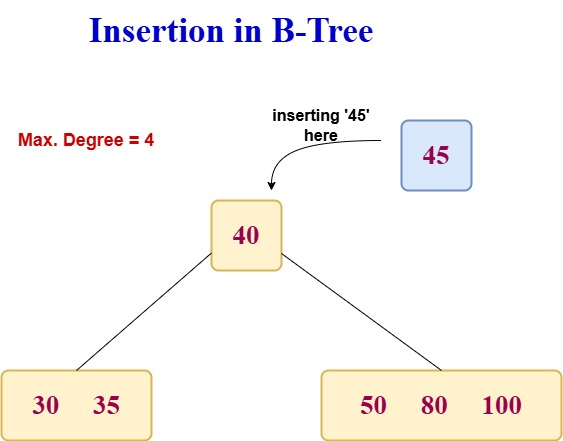
| Insert | Adds a new key in the right place and splits the node if it is full |
| Delete | Removes a key and keeps the tree balanced by joining or adjusting nodes |
| Traverse | Goes through all keys in sorted order one by one |
| Split Node | Happens when a node has too many keys and breaks into two parts |
In the section table which is mentioned below we will be covering the time complexities of all the basic B-Tree Operations in each case i.e, Best case, Average Case and Worst Case.
| Operation | Best Case | Average Case | Worst Case |
|---|---|---|---|
| Search | O(log n) | O(log n) | O(log n) |
| Insert | O(log n) | O(log n) | O(log n) |
| Delete | O(log n) | O(log n) | O(log n) |

B-Tree Usage in Databases
- B-Trees are used to store indexes in databases like MySQL and PostgreSQL. They help find rows quickly without scanning the whole table.
- File systems like NTFS (Windows) and HFS+ (macOS) use B-Trees to manage folders and files efficiently and especially when we are dealing with a large number of files.
- Some Operating Systems use B-Tree to manage memory pages or swap files, allowing quick access and updating of memory segments.
- Search engines use B-Trees in their backend to manage and retrieve index data quickly and supporting faster query results.
- In large databases B-Trees are used for multi-level indexing where indexes themselves have indexes and B-Trees keep it fast and balanced.
Advantages of B-Tree
- Balanced tree with guaranteed logarithmic operations.
- Efficient for disk-based storage systems.
- Supports range queries naturally.
- Multi-level indexing capability.
- Good cache performance due to high branching factor.
Disadvantages of B-Tree
- More Complex implementation in comparison to Binary Search Trees (BST).
- Overhead of maintaining balance through splits/merges.
- Performance can degrade without proper tuning in real-world databases.
B-Tree Implementation in C
In this section we are basically talking about how to implement B-Tree data structure in C programming language.
#include <stdio.h>
#include <stdlib.h>
#define MAX 3
#define MIN 2
struct BTreeNode {
int val[MAX + 1], count;
struct BTreeNode *link[MAX + 1];
};
struct BTreeNode *root;
struct BTreeNode *createNode(int val, struct BTreeNode *child) {
struct BTreeNode *newNode = malloc(sizeof(struct BTreeNode));
newNode->val[1] = val;
newNode->count = 1;
newNode->link[0] = root;
newNode->link[1] = child;
return newNode;
}
// Add insert, delete, search methods...
int main() {
// Insert test cases here
return 0;
}

B-Tree Implementation in C++
In this section we are basically talking about how to implement B-Tree data structure in C++ programming language.
#include<iostream>
using namespace std;
class BTreeNode {
public:
int *keys;
int t;
BTreeNode **C;
int n;
bool leaf;
BTreeNode(int t1, bool leaf1);
void traverse();
BTreeNode *search(int k);
// Insert and delete functions to be added
};
BTreeNode::BTreeNode(int t1, bool leaf1) {
t = t1;
leaf = leaf1;
keys = new int[2 * t - 1];
C = new BTreeNode *[2 * t];
n = 0;
}
void BTreeNode::traverse() {
for (int i = 0; i < n; i++) {
if (!leaf) C[i]->traverse();
cout << " " << keys[i];
}
if (!leaf) C[n]->traverse();
}
// Insert, search, delete methods go here...
int main() {
BTreeNode t(3, true);
// Use insert and traverse here
return 0;
}
Conclusion
B-Tree is a fundamental data structure and especially in systems where data is stored on disk or needs to be accessed with minimum latency. They offer an elegant balance between memory usage and access speed. With logarithmic operations and efficient range querying they are the backbone of most modern database systems.

FAQs (B-Tree)
What is the minimum degree in a B-Tree?
The minimum degree t defines the lower and upper limit of keys and children in each node. Every node (except root) must have at least t-1 keys and at most 2t-1.
How is a B-Tree different from a Binary Search Tree?
Unlike a Binary Search Tree where each node has at most two children, B-Trees allow multiple keys and children and helping keep the tree shallow and efficient for large datasets.
What is the real-world use of B-Tree?
B-Tree is commonly used in databases and file systems where quick data retrieval with minimal disk access is essential.
Can B-Trees handle duplicate values?
Yes, B-Trees can be modified to handle duplicates by storing them in child pointers or by keeping a count of duplicate keys.