
In data structures and algorithms, we study a wide range of data structures such as array data structure, linked lists, stack data structure, queue and graph data structures. As we move forward to more advanced topics, now we have B-Tree in Data Structure. The B-Tree itself is a self-balancing tree which is used to design for handling large datasets. Unlike BSTs, which will become unbalanced with certain patterns of input. B-Tree in data structure keeps its height short and its nodes are evenly distributed.
As a result, this data structure performs several operations likesearch, insertion and deletion in logarithmic time. This makes it ideal for many applications like file systems and database indexing. The B-Tree in data structure minimizes disk Input and Output by storing multiple keys in a single node.
In this blog we will talk all about B-Tree in data structure, followed by its key properties. Next, we will break down its time and space complexity, walk through different operations like insertion and deletion. Along with the practical implementation in C and C++ programming language.
What is B-Tree in Data Structure?
A B-Tree in data structure is a self-balancing search tree where each node can hold various keys and can have more than two children. It extends the concept of working in Binary Search Tree (BST) which allows each node that contains various values.
This structure helps you maintain balance even as the dataset grows that ensures efficient performance for search, insert and delete operations. One of the key advantages of using B-Tree in data structure that minimizes the disk I/O interrupts. Since each node can store several keys, the tree remains shallow and fewer reads or writes are needed to access data.
Example: Think of a library where books are kept organized on shelves by genre. Each shelf can hold a limited number of books. When a shelf gets too full, it splits into two, and the middle book moves up to a higher level shelf in B-Tree in data structures. Just like B-Tree in data structure, it remains sorted and balanced. This setup makes it easy to quickly search for the insertion operations or to remove books without scanning the entire library.

Properties of B-Tree in Data Structure
Understanding the key properties of B-Tree in data structure helps you to understand and appreciate its power of usefulness. Below are the core properties that define every valid B-Tree in data structure.
- Every leaf node in a B-Tree lies at the same level to make it structured.
- Unlike binary trees, where each node contains only one key, nodes in a B-Tree can store multiple keys. This helps in reducing the height of the tree.
- The keys inside each node are stored in a sorted manner. This ordering helps in guiding searches to the correct child node.
- The root node can have fewer than ⌈m/2⌉ children. It can even be a leaf if the tree contains very few elements.
Need of a B-Tree in Data Structure
Why Not Just Use a Binary Search Tree?
This is a common but important question as if we already have Binary Search Trees (BSTs), why do we need B-Trees? While BSTs work well in memory and for relatively small datasets, they face several limitations when applied to large-scale storage systems or disk-based operations. This is exactly where the B-Tree in data structure become invaluable.
BSTs Can Become Unbalanced
A standard Binary Search Tree (BST) can become skewed if data is inserted in a sorted or nearly sorted order. For example, inserting keys in ascending order results in a tree that resembles a linked list. This leads to the worst-case time complexity of O(n) for search, insert, and delete operations that defeats the purpose of using a tree-based structure.
On the other hand, the B-Tree in data structure ensures balance by redistributing or splitting nodes as needed during insertions and deletions. All leaf nodes remain at the same level, which keeps the height of the tree logarithmic even as data grows.
Height of BST Affects Performance
In a BST, the performance of search and update operations depends on the height of the tree. The deeper the tree, the more comparisons are required. In contrast, a B-Tree in data structure keeps its height much smaller by storing multiple keys in each node. Fewer levels mean fewer access and that translates into faster queries.
Disk Access Is Expensive
BSTs assume that each node fits into memory and can be accessed instantly. However, in systems like databases or file systems, data is stored on disk, and accessing disk blocks is significantly slower than accessing memory. Since BSTs have many levels (especially if unbalanced), a single search might require multiple disk accesses.
In contrast, the B-Tree in data structure is designed with disk access in mind. By holding many keys in a single node (which maps to a single disk block), B-Trees reduce the number of node accesses and, consequently, the number of costly disk reads.
| Feature | Binary Search Tree (BST) | B-Tree in Data Structure |
| Balancing | Can become unbalanced with skewed data | Always remains balanced |
| Node Structure | Each node contains one key and two child pointers | Each node contains multiple keys and multiple child pointers |
| Height | Can grow up to O(n) in worst case | Maintains height of O(log n) |
| Search/Insert/Delete Time | O(h), where h = height of tree (can be up to n) | O(log n), even for large datasets |
| Disk Access Optimization | Not optimized for disk-based systems | Optimized to reduce disk I/O with fewer node accesses |
| Storage Medium | Ideal for in-memory operations | Ideal for disk or external storage systems |
| Range Queries | Requires in-order traversal | Efficient due to node structure and shallow height |
Time and Space Complexity of B-Tree
Time and Space Complexity both are very important factors to analyze the efficiency of a B-Tree in data structure.
| Operation | Best Case | Average Case | Worst Case | Explanation |
| Search | O(log n) | O(log n) | O(log n) | Due to balanced height and multiple keys per node |
| Insertion | O(log n) | O(log n) | O(log n) | Insertion may cause node splits, but tree remains balanced |
| Deletion | O(log n) | O(log n) | O(log n) | May involve merging or redistributing nodes |
| Traversal | O(n) | O(n) | O(n) | Every key must be visited once during traversal |
| Space | O(n) | O(n) | O(n) | All data is stored once, with some extra pointers in nodes |

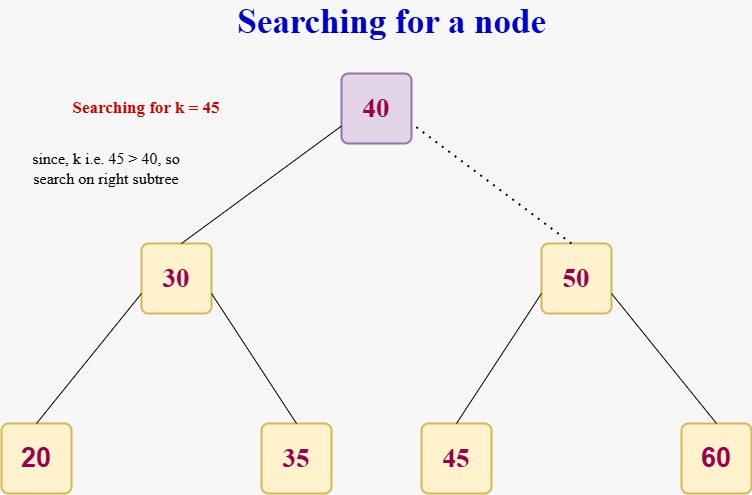
Operations on a B-Tree in Data Structure
In the given respective table for a B-tree data structure we are having all the basic operations which are required to manage the information.
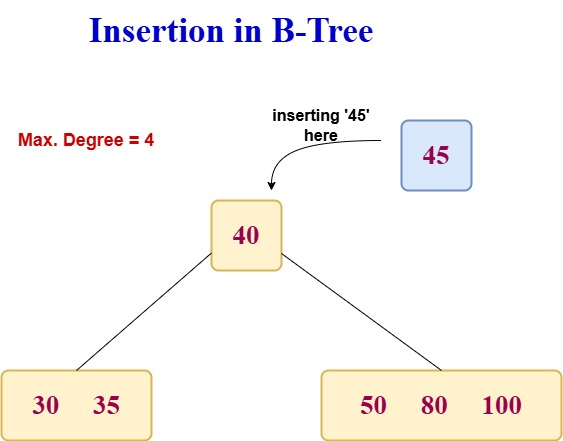
In the section table which is mentioned below we will be covering the time complexities of all the basic B-Tree Operations in each case i.e, Best case, Average Case and Worst Case.
| Operation | Best Case | Average Case | Worst Case |
| Search | O(log n) | O(log n) | O(log n) |
| Insert | O(log n) | O(log n) | O(log n) |
| Delete | O(log n) | O(log n) | O(log n) |

B-Tree Usage in Databases
- B-Trees are used to store indexes in databases like MySQL and PostgreSQL. They help find rows quickly without scanning the whole table.
- File systems like NTFS (Windows) and HFS+ (macOS) use B-Trees to manage folders and files efficiently and especially when we are dealing with a large number of files.
- Some Operating Systems use B-Tree to manage memory pages or swap files, allowing quick access and updating of memory segments.
- Search engines use B-Trees in their backend to manage and retrieve index data quickly and supporting faster query results.
- In large databases B-Trees are used for multi-level indexing where indexes themselves have indexes and B-Trees keep it fast and balanced.
Advantages of B-Tree in Data Structure
- Balanced tree with guaranteed logarithmic operations.
- Efficient for disk-based storage systems.
- Supports range queries naturally.
- Multi-level indexing capability.
- Good cache performance due to high branching factor.
Disadvantages of B-Tree in Data Structure
- More Complex implementation in comparison to Binary Search Trees (BST).
- Overhead of maintaining balance through splits/merges.
- Performance can degrade without proper tuning in real-world databases.
B-Tree Code Implementation in C
In this section we are basically talking about how to implement B-Tree data structure in C programming language.
#include <stdio.h>
#include <stdlib.h>
#define MAX 3
#define MIN 2
struct BTreeNode {
int val[MAX + 1], count;
struct BTreeNode *link[MAX + 1];
};
struct BTreeNode *root;
struct BTreeNode *createNode(int val, struct BTreeNode *child) {
struct BTreeNode *newNode = malloc(sizeof(struct BTreeNode));
newNode->val[1] = val;
newNode->count = 1;
newNode->link[0] = root;
newNode->link[1] = child;
return newNode;
}
// Add insert, delete, search methods...
int main() {
// Insert test cases here
return 0;
}

B-Tree Code Implementation in C++
In this section we are basically talking about how to implement B-Tree data structure in C++ programming language.
#include<iostream>
using namespace std;
class BTreeNode {
public:
int *keys;
int t;
BTreeNode **C;
int n;
bool leaf;
BTreeNode(int t1, bool leaf1);
void traverse();
BTreeNode *search(int k);
// Insert and delete functions to be added
};
BTreeNode::BTreeNode(int t1, bool leaf1) {
t = t1;
leaf = leaf1;
keys = new int[2 * t - 1];
C = new BTreeNode *[2 * t];
n = 0;
}
void BTreeNode::traverse() {
for (int i = 0; i < n; i++) {
if (!leaf) C[i]->traverse();
cout << " " << keys[i];
}
if (!leaf) C[n]->traverse();
}
// Insert, search, delete methods go here...
int main() {
BTreeNode t(3, true);
// Use insert and traverse here
return 0;
}
Conclusion
B-Tree is a fundamental data structure and especially in systems where data is stored on disk or needs to be accessed with minimum latency. They offer an elegant balance between memory usage and access speed. With logarithmic operations and efficient range querying they are the backbone of most modern database systems.

FAQs (B-Tree in Data Structure)
What is the minimum degree in a B-Tree?
The minimum degree t defines the lower and upper limit of keys and children in each node. Every node (except root) must have at least t-1 keys and at most 2t-1.
How is a B-Tree different from a Binary Search Tree?
Unlike a Binary Search Tree where each node has at most two children, B-Trees allow multiple keys and children and helping keep the tree shallow and efficient for large datasets.
What is the real-world use of B-Tree?
B-Tree is commonly used in databases and file systems where quick data retrieval with minimal disk access is essential.
Can B-Trees handle duplicate values?
Yes, B-Trees can be modified to handle duplicates by storing them in child pointers or by keeping a count of duplicate keys.



{kind=link}